

【儀表網(wǎng) 研發(fā)快訊】近日,南方科技大學深港微電子學院林龍揚課題組在非易失存算一體芯片領域取得重要研究進展,提出并流片驗證了首個精度無損、全并行的數(shù)字式非易失存算一體芯片,系統(tǒng)性解決了傳統(tǒng)模擬式存算一體芯片在計算精度、可擴展性與魯棒性上的瓶頸。相關成果以“A lossless and fully parallel spintronic compute in memory macro for artificial intelligence chips”為題在學術期刊Nature Electronics在線發(fā)布。
人工智能芯片的性能正日益受到傳統(tǒng)馮·諾依曼架構中“存算分離”模式的制約,頻繁的數(shù)據(jù)搬運會造成高能耗與高延遲。非易失存算一體(nvCIM)架構將矩陣向量乘法(MVM)直接嵌入存儲單元執(zhí)行,能夠顯著降低數(shù)據(jù)移動的開銷,為突破這一瓶頸提供了可行路徑。然而,當前主流的模擬式nvCIM 架構存在計算精度受限、工藝電壓溫度波動影響大、可擴展性差等問題。此外,在先進制程下,模擬電路中數(shù)模/模數(shù)轉換器的設計也面臨精度降低、面積與功耗開銷增大等挑戰(zhàn),限制了系統(tǒng)的可擴展性與魯棒性。這些制約因素使得模擬式nvCIM難以勝任物理信息神經(jīng)網(wǎng)絡(PINN)等對計算精度和可靠性要求嚴苛的人工智能驅動科學(AI for Science)研究任務。因此,如何在非易失存儲上實現(xiàn)兼具高能效、高通量、全精度數(shù)字式計算,已成為該領域亟待突破的核心難題。
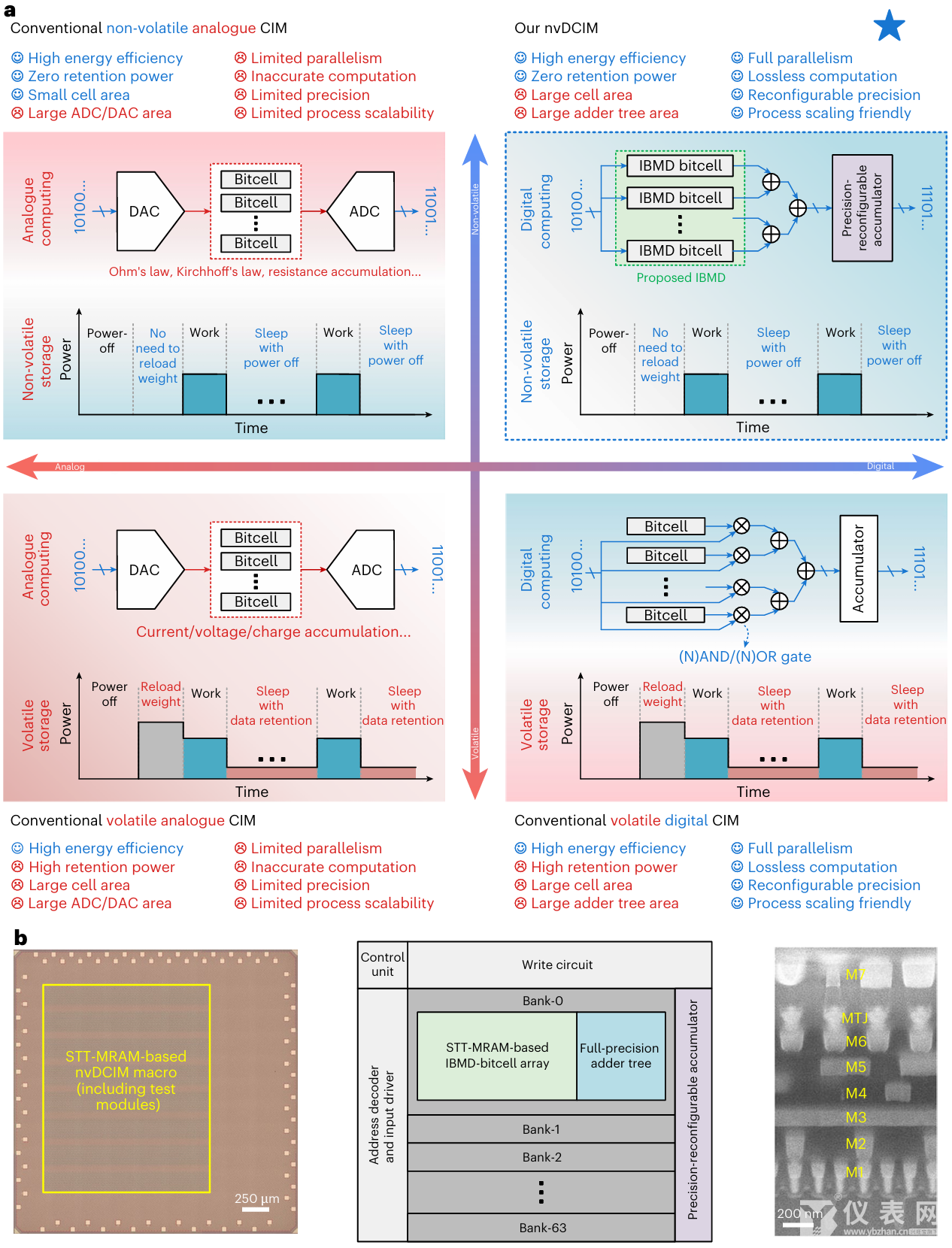
圖1. 基于非易失存儲的數(shù)字存算一體(nvDCIM)芯片的動機與概述
針對上述挑戰(zhàn),研究團隊基于40納米CMOS及STT-MRAM工藝,成功設計并流片驗證了一款64kb非易失數(shù)字式存算一體(nvDCIM, non-volatile Digital Compute-in-Memory)芯片(圖1)。該芯片在存儲單元、電路與算法三個層面實現(xiàn)了系統(tǒng)性創(chuàng)新:
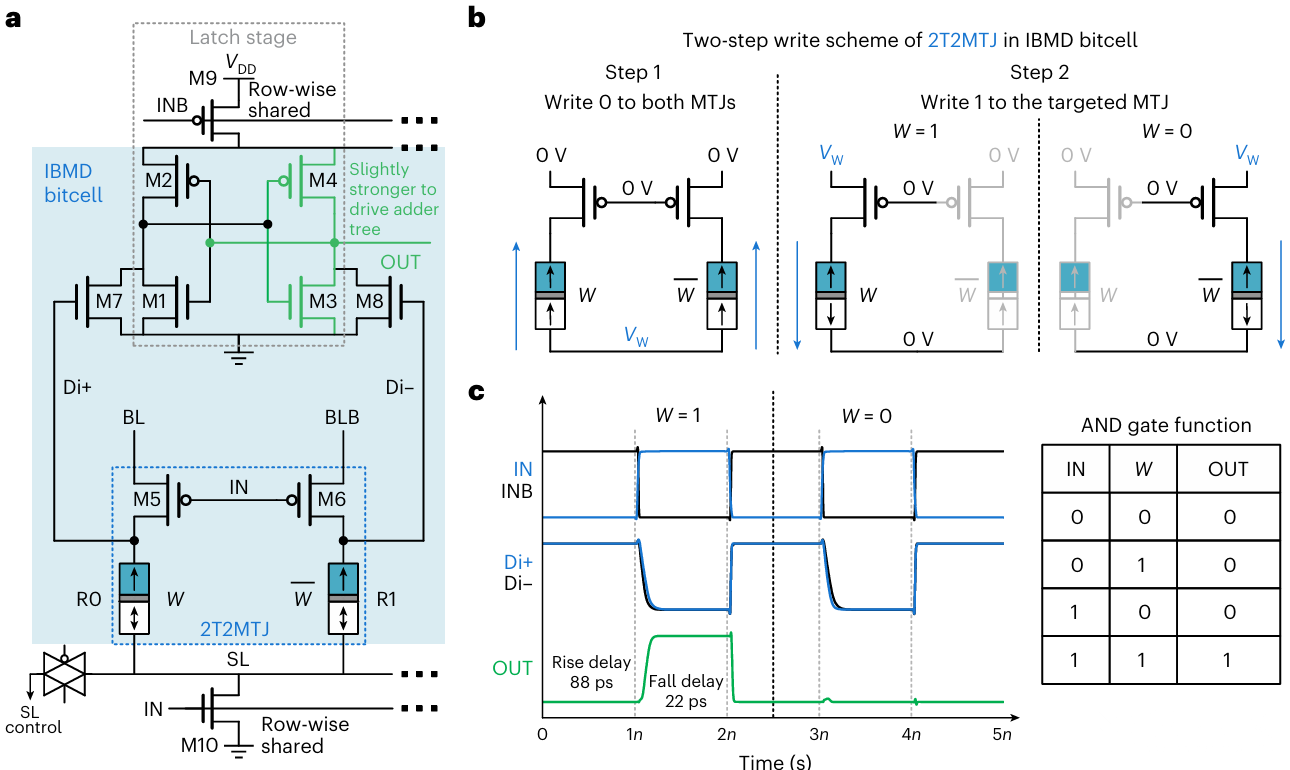
圖2. 單元內乘法與數(shù)字化
在存儲單元層面,研究團隊提出“單元內乘法與數(shù)字化”(IBMD,In-Bitcell Multiplication and Digitization)(圖2),在STT-MRAM位單元中實現(xiàn)單比特輸入與存儲權重的乘法運算,并直接輸出數(shù)字化結果,等效實現(xiàn)數(shù)字“與”邏輯。該設計從源頭避免使用模擬式nvCIM中常見的數(shù)模/模數(shù)轉換器,有效提升了系統(tǒng)的魯棒性與可擴展性。
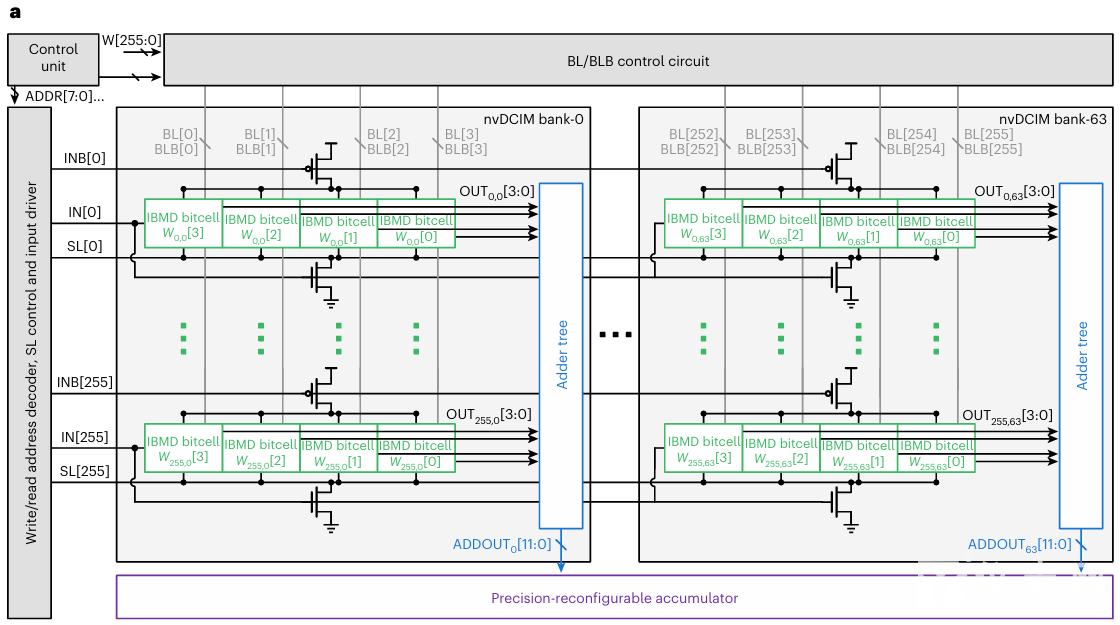
圖3. 芯片電路架構
在電路層面,研究團隊實現(xiàn)了全精度加法樹與精度可重構累加器(圖3),支持4/8/12/16比特多種精度配置的輸入與權重,實現(xiàn)了全并行、精度無損的MVM,在保證計算精度的同時大幅提升吞吐率。
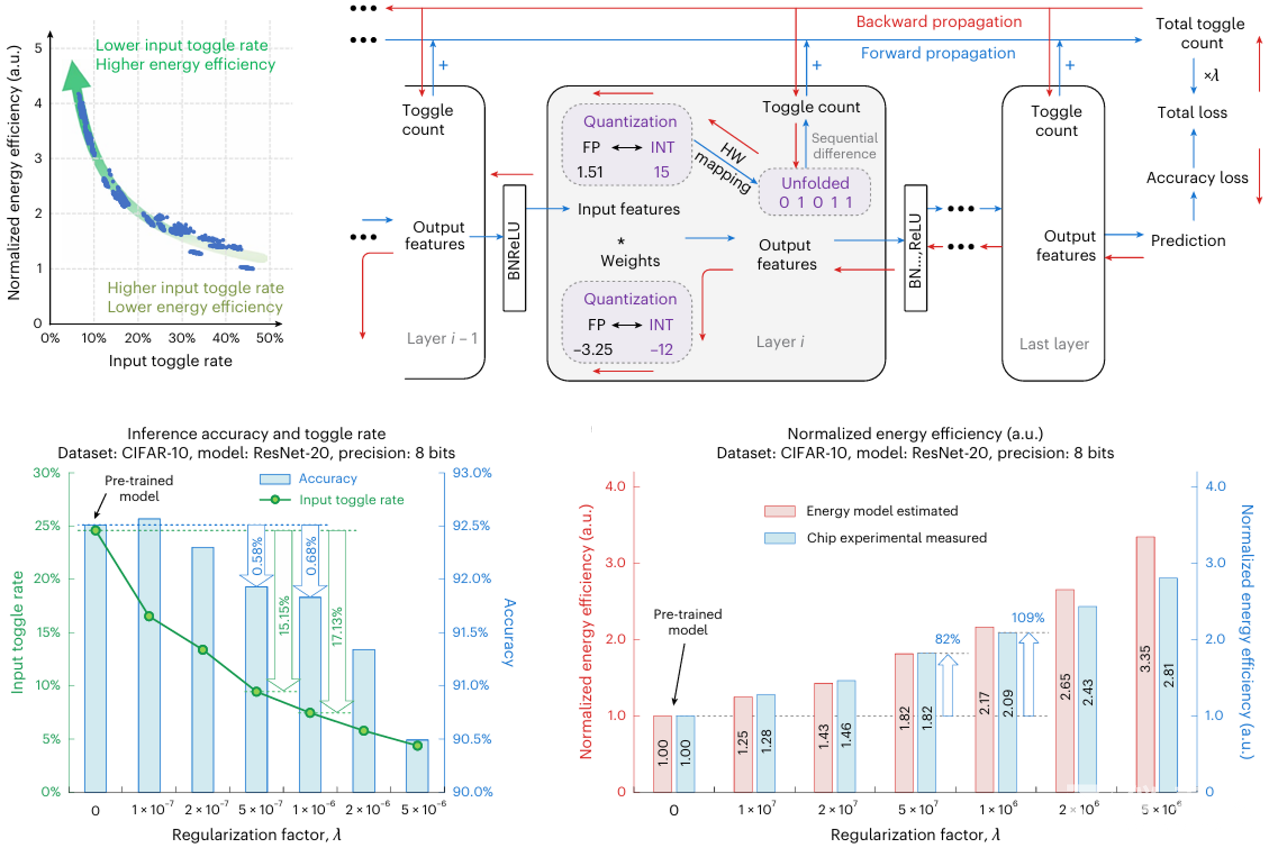
圖4. 翻轉率感知訓練方法
在算法層面,團隊提出翻轉率感知訓練方法(Toggle-rate-aware Training)(圖4),通過將存算一體陣列輸入信號的比特翻轉率作為正則項,融入神經(jīng)網(wǎng)絡損失函數(shù)中進行聯(lián)合優(yōu)化。該算法在不降低模型任務精度的前提下,顯著降低了芯片在執(zhí)行推理過程中的動態(tài)功耗,實現(xiàn)了軟件與硬件協(xié)同優(yōu)化能效的目標。
該研究展現(xiàn)了nvDCIM架構在實現(xiàn)高吞吐、高能效、無損數(shù)字式計算方面的綜合潛力,為下一代高能效AI芯片提供了一條可靠路徑。IBMD單元設計不僅成功在STT-MRAM中實現(xiàn)了高速數(shù)字邏輯運算,還可進一步推廣至其他阻性非易失存儲技術,拓寬nvDCIM的技術路線與應用場景。未來,團隊將繼續(xù)優(yōu)化電路設計與芯片架構,推動存算一體芯片向更大容量發(fā)展,并探索在復雜AI系統(tǒng)中的集成應用。通過軟硬件協(xié)同優(yōu)化策略,該技術有望為打破“內存墻”、推動邊緣與云端智能設備的高效能部署奠定堅實基礎。
該研究由南方科技大學聯(lián)合西安交通大學等單位共同完成,南方科技大學為論文第一單位和通訊單位。南方科技大學林龍揚助理教授、西安交通大學閔泰教授為論文通訊作者。南方科技大學林龍揚課題組2024級博士研究生李瑚淼(南科大2018級本科畢業(yè)生,2022級碩士研究生)為論文第一作者。本研究獲國家重點研發(fā)計劃、國家自然科學基金、深圳市高等院校穩(wěn)定支持計劃等項目資助。




















所有評論僅代表網(wǎng)友意見,與本站立場無關。